All Sync Blog Posts
Conflict Resolution in CouchDB with Fauxton posted Wednesday, October 15, 2025 by The Neighbourhoodie Team CouchDBDataSync
One of the key aspects of CouchDB is how it handles concurrent updates. It is built for replication and offline-first or local-first use cases where multiple users and devices edit the same document independently and sync back their changes later. Instead of silently discarding a user’s changes when two users edit the same document, CouchDB keeps track of the conflicts: situations where two or more versions of a document exist simultaneously.
Partial Data Fetching on Initial Load with PouchDB and CouchDB posted Wednesday, July 16, 2025 by The Neighbourhoodie Team PouchDB CouchDB Sync Tip
If you’re building an offline-first or local-first app, you’ll eventually run into a problem concerning the initial loading of data onto the device: it gets a bit slow, and users end up having to wait for the initial sync to complete before they can do anything. This is such a prevalent issue that there was even a session on it at Local-First Conf recently. We’d like to share a strategy for dealing with “Partial Data Fetching on Initial Load” from experience with PouchDB and CouchDB. Get fast time-to-idle and synced data at the same time!
How to Sync Anything: Building a Sync Engine from Scratch — Part 3 posted Wednesday, April 23, 2025 by Jan Lehnardt CouchDB Replication Sync Distsys Data
Note: This is part of our series demystifying synchronisation. See our other instalments: How to Sync Anything: Introduction and How to Sync Anything: Building a Sync Engine from Scratch — Part 1 and How to Sync Anything: Building a Sync Engine from Scratch — Part 2
Last time we learned how to efficiently decide what needs syncing. This time we will learn how to version our data.
How to Sync Anything: Building a Sync Engine from Scratch — Part 2 posted Wednesday, April 16, 2025 by Jan Lehnardt CouchDB Replication Sync Distsys Data
Note: This is part of our series demystifying synchronisation. See our other instalments: How to Sync Anything: Introduction, How to Sync Anything: Building a Sync Engine from Scratch — Part 1 and How to Sync Anything: Building a Sync Engine from Scratch — Part 3
In this part, we will learn how to efficiently find out what data needs to be synchronised.
How to Sync Anything: Building a Sync Engine from Scratch — Part 1 posted Wednesday, April 9, 2025 by Jan Lehnardt CouchDB Replication Sync Distsys Data
There’s an old saying I paraphrased in this by now ancient tweet[sic]:
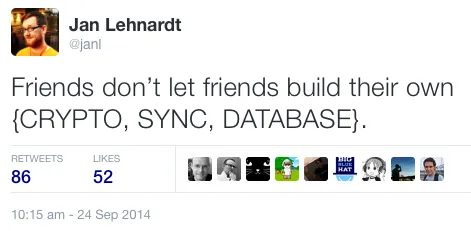
“Friends don’t let friends build their own {CRYPTO, SYNC, DATABASE}.” — @janl on September 24th, 2014
What do I mean by that?
How to Sync Anything posted Sunday, April 6, 2025 by James Coglan CouchDB Replication Sync Distsys Data
In this article I’ll discuss a common naive solution to replication, why it doesn’t work, and what the building blocks of a good solution look like. Having established this theoretical framework, my next article will look at how CouchDB provides many of those building blocks such that replicating from it into any other system is relatively painless.
Offline-First with CouchDB and PouchDB in 2025 posted Wednesday, March 26, 2025 by The Neighbourhoodie Team Tip CouchDB Sync Offline-First
A few weeks ago, we gave you tooling to quickly and easily host your own CouchDB: CouchDB Minihosting! This week, we’re providing a demo application you can deploy on that installation, so you can try that part out with zero hassle. On top of that, consider this an up-to-date, best practises demo app for Offline-First with CouchDB and PouchDB. We’re using Svelte 5 with Vite as build tooling and Pico.css for styles.
From Dig Sites to Data Sync: iDAI.field and Offline-First Systems for Archaeology posted Thursday, March 20, 2025 by The Neighbourhoodie Team Interview CouchDB Sync Case study
Reliable data collection during archaeological field work in remote locations comes with a multitude of challenges. Even in the most isolated dig sites, capturing, storing and synching need to happen seamlessly and with zero data loss. Offline-First can solve half the problem. What about the half that needs to bring together teams and findings from across the globe?