First Steps: Sharding in CouchDB posted Wednesday, October 1, 2025 by The Neighbourhoodie Team CouchDBDataTipPerformance
While other databases out there might shard, CouchDB is one of the few that does it automatically and saves you the annoying — read error-prone — work of setting it up yourself. Being unique in this way, it’s a topic you may not know too well. The arcane-sounding term (especially if it reminds you of the prismatic variety) doesn’t need to conjure confusion or intimidation. In this post, we’re going to take a deeper look at scaling CouchDB with shards: what sharding is, plus why and how to do it.
What Sharding is & Why it’s Useful
Any given central processing unit (CPU) — the thing on which your database lives — has a physical limit to how much processing it can do at one time.
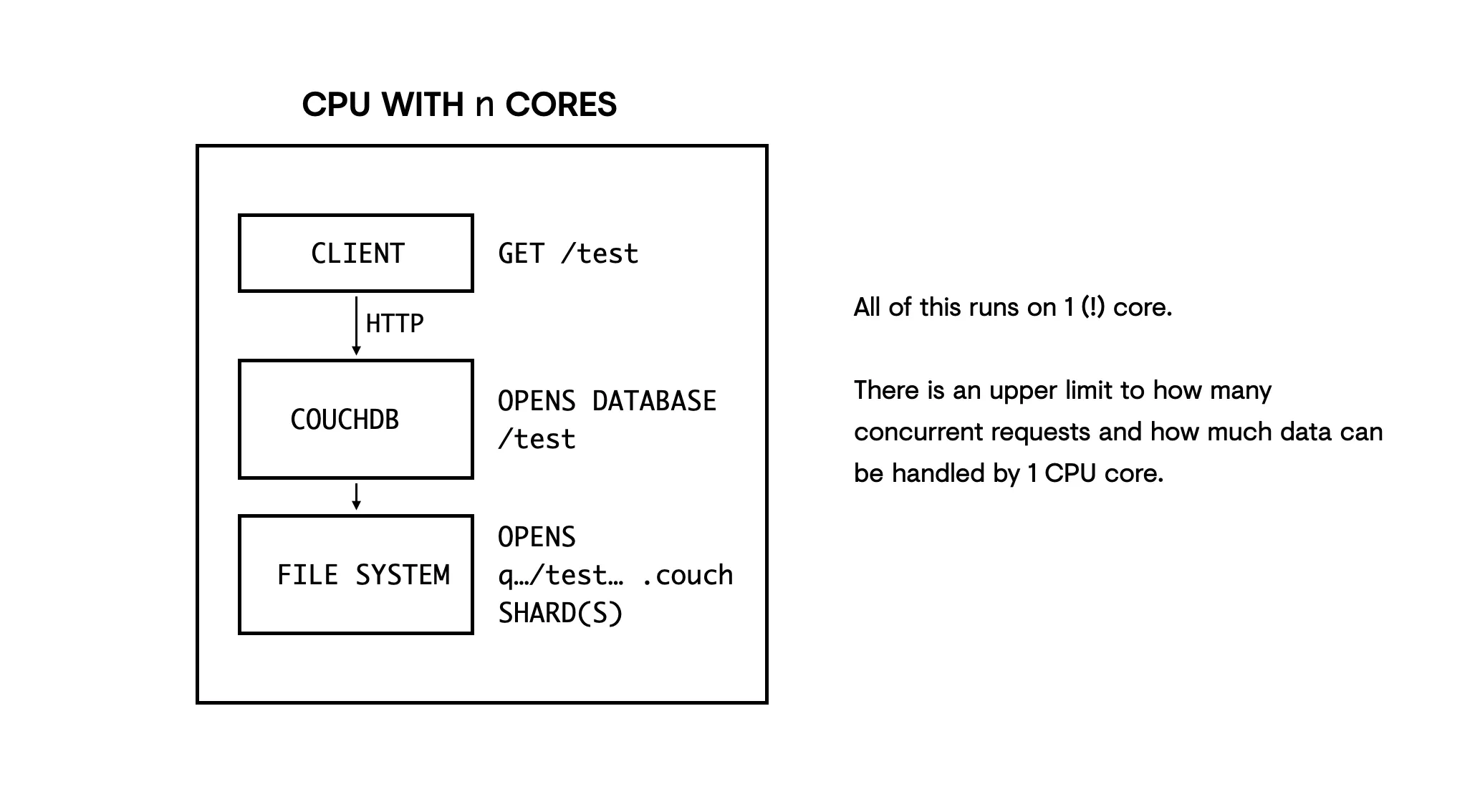
By extension, there’s a limit to how big your database can get if you still want to do useful things with it if it can only run on a single core.
Databases each provide their own method to scale with your data and request load as they increase, enabling higher and higher volumes of traffic, more and more reads and writes. Broadly speaking, databases handle this load in one of two ways: scaling vertically or horizontally.
Vertical Scaling
This usually means throwing more resources at the machine running your database. If you rely on cloud computing, that might mean going up an EC2 machine size, or if you are running your own machines, migrating your database to a new server with more CPUs or CPU cores. Faster network connection on the new server will also help. However you choose to do it, the goal is to increase processing capacity provided by hardware and/or infrastructure.
The major pro of this approach is that by staying focused on the hardware level, you don’t have to deal with the complexities of distributed databases.
The cons are that each step you take up in computing power comes with a price tag, and you’re limited in terms of how far you can scale up by how big the biggest available machine at the time is.
Horizontal Scaling
The other way you can take things mainly means splitting the data you have into logical partitions. These parts can then be distributed across multiple CPU cores and even across multiple computing nodes. By doing so, you can change the way data is processed to make more efficient use of existing resources rather than having to buy ever higher-performance servers. If you opt for a horizontal scaling strategy, then adding hardware resources looks like adding more of the same kind of servers onto which data are distributed.
The biggest pro here is that you can scale beyond the capacity of a single machine. Also, combining multiple smaller machines is cheaper than splurging on the one really powerful machine you’d need to scale vertically.
The usual con in a horizontal scaling scenario is that distributed databases add a lot of complexity. I say usually because CouchDB’s clustering features make a lot of this go away, and instead your cluster looks like a single, but powerful and redundant server.
CouchDB is especially good at horizontal scaling. One of the ways it works around physical limitations is by using shards, the logical parts it can create and distribute. Shards also mean CouchDB has the performance benefit of shorter access paths. If you logically split shards along document ids, for example, then you can get much faster read and write performance since each shard now has a log(1/number-of-shards) shorter path to the document itself. This means you can get away with less powerful — read cheaper — hardware.
Another benefit CouchDB gains by using shards is that you can even further distribute your required computing across multiple nodes when replicas are all on their own machine.
Databases that Shard
Let’s approach databases that shard in terms of two categories: relational and NoSQL.
In relational databases — as the name suggests — various pieces of data are closely coupled with one another. This makes sharding inherently difficult because there is a lower limit to how data can be de-coupled and split in a schema. Because it’s not what they were strictly designed to do, popular relational databases like Postgres, MySQL and MSSQL rely on third-party sharding extensions. Citus for Postgres, for example, enables sharding and uses reference tables replicated to all nodes to get around distributing data relations. One notable exception to this is OracleDB, which might be the only SQL database with native sharding capabilities.
Now for the NoSQL databases. Noteworthy in this category is MongoDB, which does shard, but not automatically —you have to enable it. Also, confusingly, MongoDB conflates sharding and setting up a cluster, which can be a bit confusing.
So, CouchDB remains somewhat an outsider in that it’s one of the few database systems that shards automatically and transparently, as in: your application is none the wiser and just benefits from the additional hardware resources as you grow.
Sharding in CouchDB
In CouchDB, a shard is a file on disk with a .couch ending. You can also configure how many replicas your database will make of each shard in a scenario where you have more than one node.
When it comes to configuring your shards, there are two important values to keep in mind:
- One is
q, which is the number of shards per database. In CouchDB, sharding can be controlled per database and doesn’t have to be an overarching instance configuration. You can have one database in four shards, one in two shards and another with one shard, for example. The default value is 2, and we’ll cover guidelines for a limit per shard a bit later on. - The other parameter is
n, which is the number of shard replicas. Shard replicas make sure you have multiple, independent copies of your data distributed across multiple nodes — which is when this parameter becomes interesting — but no node can have more than one replica of the same shard. For a single node, by defaultn = 1. Having multiple replicas of the same shard on a single node doesn’t have benefits for data resilience and would just waste disk space.
A database can be stored in 1…n shard files. Each shard is still limited by a single CPU, but 2 shards can be handled by 2 separate CPU cores. 4 shards can be handled by 4 cores, 8 shards by 8 cores, and so on. Very large databases can have a q of 16, 32, 64 or more.
For a cluster, the default number of shard replicas or n value is 3. So for example if you have q = 2 and n = 3 (which is the default in the cluster) you would have 6 shards in total, per database.
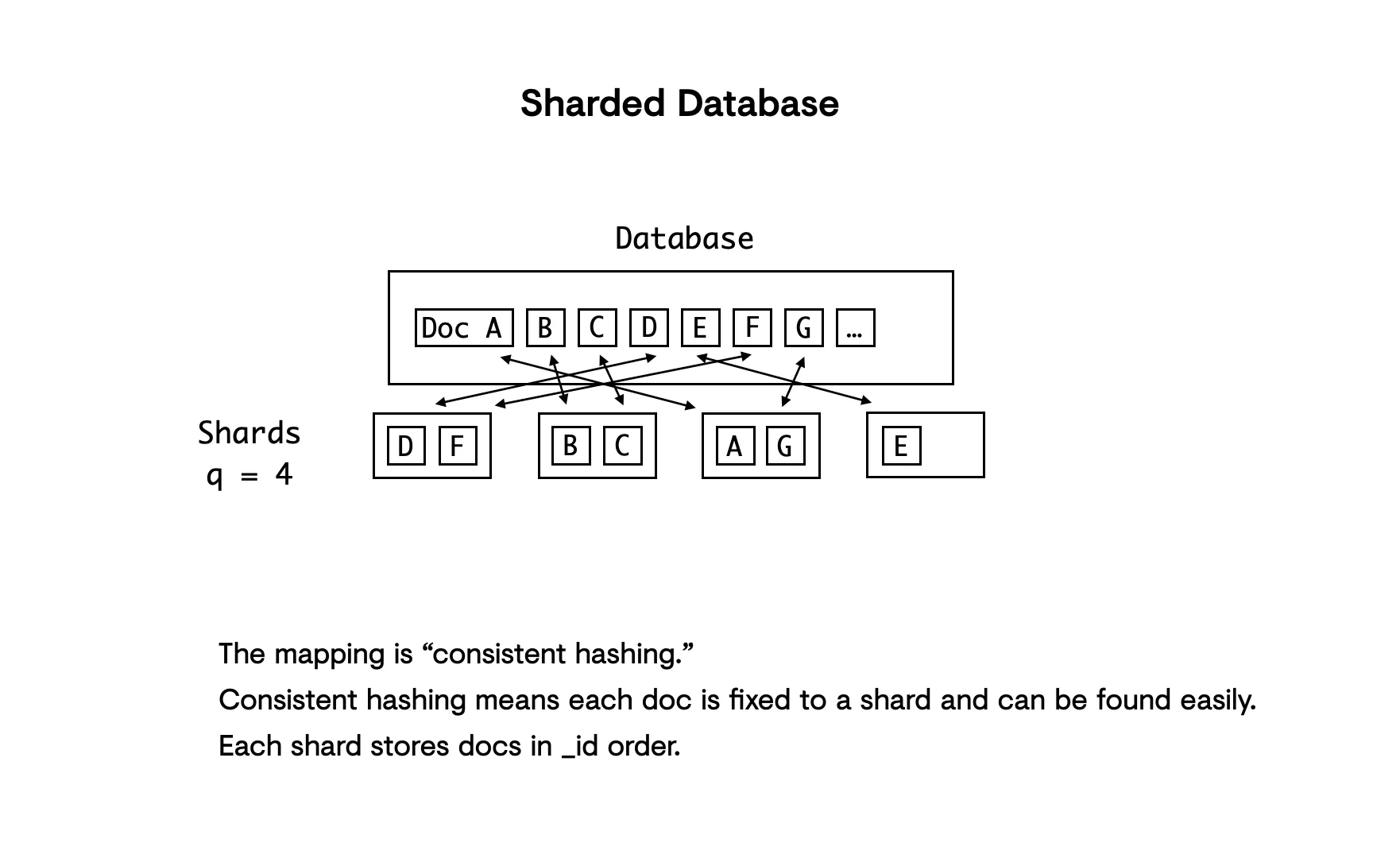
In CouchDB shard ranges are hashed from the document IDs using the CRC 32 hash, which achieves a relatively uniform hash distribution. What this means is that you don’t need to worry about your ID distribution, because CouchDB hashes your document IDs before adding them to a shard. The result is that shards won’t be — or will very rarely be — different in size. Usually shards are fairly evenly balanced (unless you have a lot of attachments or conflicts, but that is not a sharding concern).
Here’s an example showing two shards in a database:
Shard 1: Hashed IDs 00000000-7fffffff
Shard 2: Hashed IDs 80000000-ffffffffOne shard has the hexidecimal range 00000000-7fffffff, and the other shard has the range from 80000000-ffffffff. All your document IDs will be hashed to fit into one of these ranges and each ID here has a ~50% chance of landing in either one.
A major benefit of sharding in CouchDB is more efficient view indexing. By having multiple parts of your data, you can process view indexes in parallel. CouchDB can spawn q couchjs processes, effectively doubling the throughput for each doubling of q. This works as long as the respective amount of CPU cores are available.
Doing Stuff with CouchDB Shards
Let’s quickly have a look at some cool stuff you can do with shards. The most basic thing you can do is to send an HTTP GET request to your database to check its sharding parameters:
curl -s http://mynode1:5984/mydbname{
…
"cluster": {
"q": 2,
"n": 3,
"w": 2,
"r": 2,
}
…
}Here we can see the cluster key which tells us the value of q and of n. We can also see values for w and r, read and write quorums which, for the sake of staying on topic, we won’t go further into in this article.
We can also find out where exactly shard replicas are placed in a cluster by calling the mydbname/_shards endpoint:
curl -s http://mynode1:5984/mydbname/_shards{
…
"shards": {
"00000000-7fffffff": [
"mynode1@localhost",
"mynode2@localhost",
"mynode3@localhost",
]
},
…
}We can see that the first shard, with shard range 00000000-7fffffff is stored on node 1, 2 and 3 — exactly as it should be. In a scenario with four nodes where n = 3, it might (correctly) be 1,2 and 4.
One cool thing you can do is split an existing shard into two smaller ones using the _reshard endpoint:
curl
-X POST http://mynode1:5984/_reshard/jobs
-H "Content-Type: application/json"
-d '{
"type": "split"
"db": mydbname",
"range": "00000000-7fffffff"
}'
-s
[{"ok":true, …}]
#q will now be 3 for this database
#Keep in mind that shard ranges are now
#unbalanced unless you split the other range too.In this request, we’re asking CouchDB to split the shard with range 00000000-7fffffff on this database:
- By adding a shard we’re changing the
qvalue to 3 - And end up with three shards:
- One untouched shard, in its original size
- Two smaller shards split from one shard, equal in size to each other but half the size of the untouched shard
While this is very neat to do, don’t forget that leaving our CouchDB as-is after sending this request and keeping shards of differing sizes would not be ideal, and can lead to degraded performance. We’d want to split our other shard too and have q = 4, and as a rule of thumb, when increasing the number of shards, always ensure we’re splitting all shards and keeping them roughly equal in size.
Reducing your q value is not possible in CouchDB out-of-the-box: the _reshard endpoints only support splitting shards up, not down. But if you were hoping to read the contrary we have good news! At Neighbourhoodie we developed a little NodeJS CLI tool called couch-continuum that reduces the number of shards for you.
The procedure is not too difficult, and you could still reduce shards manually if you wanted to. It basically consists of creating a new, replica database with the new q value, replicating your data there, and then destroying the original source database, recreating it with the new q value and replicating the data back. This solution will incur some downtime. You could avoid that by updating your application code to point toward the replica database, but that’s a topic a bit beyond the scope of this article. Suffice it to say it requires some consideration.
Things to Consider in Production
The first thing we recommend is to start with the default q value of 2 (since CouchDB 3 onwards) and split your shards with the _reshard endpoint as your database grows. This takes away a lot of the stress of choosing your q value up-front, because as we’ve seen, it’s much easier to go up in q values than to go down. Providing a larger q value than you need would mean consuming more resources than you need to, for no clear benefit. CouchDB will tend to consume the resources you give it, and a large q value will set it on a hungry path. We’ll look at rough guidelines for a limit per shard in the next section.
Another rule of thumb: n should always be at least equal to the number of nodes in your cluster, but not more than 3. It’s kind of self-explanatory: you’d want your system to make use of the breadth of infrastructure you’ve made available to it, you can’t just have a full copy of all data on each shard. And also, having three copies means that if one node fails for some reason, you still have redundant access to your data, so while you wait for that node to recover or be replaced, you can still lose one more node and your application is, again, none-the-wiser. It is very unlikely that you need to protect against even more cascading errors beyond that.
Rough Guidelines for a Limit per Shard
As a very general rule of thumb, and depending on your attachment sizes, we recommend increasing your shard limit or q value when each shard has:
- 1GB — 10GB active data size per shard, or
- 1M — 10M documents, whichever comes first.
Additionally, if you have 1000s of requests and one of your CPU cores peaks at 100%, you might run into the limit. If you observe this level of usage, it’s sensible to upscale.
Good to Know Before Sharding
There are potential downsides to sharding, depending on your use case or frequent processes you might need your system to run:
- View joins
- Mango
_all_docs- and
_changes
tend to cause more resource usage, as each request needs to talk to q shards. Partitioning can help by collecting data with a common prefix on a single shard instead of distributing the data evenly across shards. We’ve written about how partitioning works and which use cases it’s suited to: check it out if your project will be join or _all_docs-heavy, for example.
Splitting Shards
We mentioned this before, but it’s important that your shards are of a similar size to one another in order to avoid performance quirks. You should always split shards quadratically:
- 2 → 4
- 4 → 8
- 8 → 16
- 16 → 32
- …
Consider Document Design
Shards help you do some pretty cool stuff with CouchDB! But if you’re not configuring CouchDB correctly, or if you don’t have a sound and reasonably considered approach to document design, sharding won’t help you mitigate the impact of that.
One of the most important things to think about early in CouchDB is how you’ll achieve a consistent and scalable document model. CouchDB can do a lot of things, but it can’t do everything, so getting your docs in a row ( 🦆!) is your best way to ensure steady performance from the outset. We’ve written up a couple of tips to get you going:
Conclusion
Shards serve multiple purposes in CouchDB — they’re essential to its scaling strategy and data availability, and a key part of using CouchDB as a distributed system. Most importantly, you mostly won’t have to think about shards as CouchDB handles them for you transparently. Only when your application becomes a major success will you have to take them into account, and even then they’re pretty straightforward to handle and your application will not need a rewrite.
We recommend diving more deeply into the topic in the official CouchDB Docs.
This article owes a huge debt to Olivia Hugger and is based on her presentation Sharding in CouchDB for Fun & Profit which you can watch, in full, on our YouTube channel.
If you would like insights to help optimise your architecture, need a CouchDB monitoring tool, or don’t yet know what you need — give us a call. We are curious and would love to help you and your project be successful.
« Back to the blog post overview