Why Choose CouchDB in 2025: Annual Apache CouchDB User Survey Results posted Wednesday, June 18, 2025 by CouchDB Team CouchDBNews
It’s been a minute, but we’re back at it! We’re very happy to have resumed this initiative and report on the Annual Apache CouchDB User Survey. We’re as eager as you to learn what everyone is thinking, so without further ado, let’s go!
“I’ve had 0 production issues in 15 years.”
Goal of the Survey
The goal is simple: to help contributors understand usage and challenges, which has the knock-on effect of helping users quell some curiosities when it comes to learning how others are using CouchDB. To put it even more simply, the survey is our way of learning what CouchDB does in the wild.
To give it some structure, we’ll go through results by section:
- Adoption
- Features
- Challenges
And we’ll be focusing on headline trends. For a more granular breakdown, see the report on the CouchDB blog or view the raw data.
1. Adoption
CouchDB was the first database to store all data in JSON, setting the standard for modern databases, and for using an HTTP server which means you can get going without libraries (among other notable brags). Its community size has remained stable for around the last 15 years, and it became a core technology associated with Offline-First in around 2013, and more recently with Local-First. At its current size, the Apache CouchDB team regularly ships significant updates, and new libraries enter the eco-system as others fall out of date. While some mentioned they’d like to see wider CouchDB adoption, praise for the community and its honesty confirmed that many value the sustainable and independent nature of CouchDB. It’s not going anywhere, and it’s staying open source. If anything, CouchDB is ready for the curve to catch up. One thing no one would be prepared to trade-off is CouchDB’s reliability.
More than 60% of you had upgraded to CouchDB 3.4.2 within 3 months of it being available — easy to do because CouchDB goes to great lengths to ensure that nothing breaks when you upgrade. It’s great to see more people taking advantage of that.
When we checked in during the 2017 survey, replication and ease-of-use were frequently mentioned as the dominant reasons to work with CouchDB. This time around, in terms of replicating with CouchDB, even more devs are using PouchDB as the favourite:
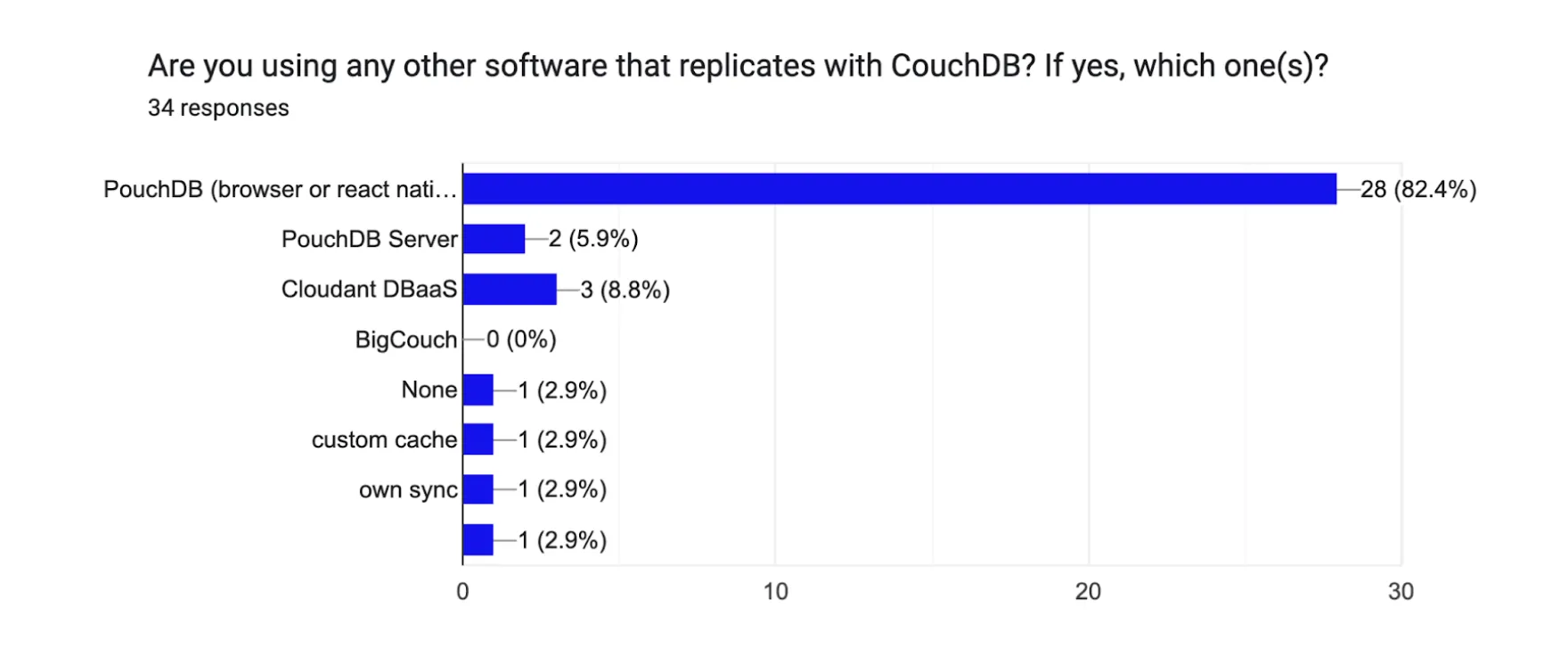
Previously, 19 technologies found their way onto the list. While PouchDB was a favourite then too, we’re happy to see it has become even more of a go-to.
2. Features
There are four clear winners for most-loved feature: replication, the changes feed, CouchDB’s HTTP API and lastly, clustering.
Replication is probably the CouchDB feature, and is the reason a lot of people choose it in the first place. If you’ve ever tried to build a sync engine from scratch, you’ll know that database replication behaviours can vary wildly, with often unintended consequences. Because it’s at the heart of what it does, CouchDB’s fast, comprehensive and flexible replication behaviour ideally supports offline-first and local-first use cases. There’s a reason the phrase “it just works” comes up again and again in the survey.
Unsurprisingly, the most loved feature in conjunction with replication is the changes feed. The sequential list of changes can be used to initiate actions in event-driven workflows, and supports use cases like real-time dashboards, starting actions based on incoming data, and exporting data from CouchDB into other database systems.
The HTTP API is another feature we weren’t surprised enjoyed a lot of praise. Aside from making it easier to work with everything in JSON, it means that practically everything has a URL in CouchDB — from restarting the database to initiating a sync — which makes it very fast to get up and running.
So far we’ve seen that CouchDB is loved for its sync, that its powerful API helps you get going without too much learning or much of a stack, and because it makes it very easy to react to database changes in your application design. These will get you out the gate in a flash, but CouchDB’s clustering is what will get you up the hill without a sweat.
It’s one of the things that helps CouchDB scale horizontally as well as vertically, and enables you to work with massive data sets easily. The scaling capability is so significant we’ve seen very few teams come anywhere close to an uncomfortably stretched edge of a CouchDB in 11+ years.
“In use to replicate onboard data of 100+ [sea-faring] vessels around the globe to the cloud.”
3. Challenges
We’ve covered what CouchDB does with ease and what it’s loved for. Now let’s look at the flip-side: the necessary trade-offs. The two most-mentioned challenges had to do with querying and hosting. There were also mentions of tombstone management.
If you’ve previously only used SQL databases, then NoSQL takes some getting used to. For starters, freeing data and making a database easy to scale comes at the expense of complex queries. To be fair, there may be aspects of SQL querying you’ll always miss. CouchDB is not different in this regard (but that’s also why we created Structured Query Server).
While this survey contained a lot of praise for faster indexing, faster querying and reduced memory usage (all thanks to 3.4.2’s QuickJS addition), querying is frequently mentioned on the “least-loved” list.
There are several ways you can query CouchDB:
- Map/reduce views are the primary way to build indexes, extract data and perform calculations. It’s powerful at getting data you’ll need repeatedly, like aggregating things for a status dashboard.
- Mango Queries steps in to make ad-hoc querying more efficient by supporting simple queries.
- Nouveau is CouchDB’s new full-text search. It can handle everything from fuzzy search to facets, bringing even more query power to CouchDB. We’re so excited for this one, we put together a guide to get started with Nouveau.
Interestingly, some users replicate their primary CouchDB to an SQL database for querying and reporting purposes.
Next up is tombstone management. Did I already mention that CouchDB takes your data integrity very seriously? In addition to being append-only, CouchDB also doesn’t completely delete documents. Aside from fulfilling a human need, if it did, another instance would simply replicate the “missing” document right back to the db you deleted it from. Instead, CouchDB marks the deleted file with a tombstone. The trade-off to ensuring sync just works and documents don’t disappear: pruning old revisions.
Lastly: hosting. CouchDB doesn’t yet have a turnkey hosting solution for projects before they hit enterprise scale. Once they do, IBM’s Cloudant is available, but in the meantime, users responding to the survey feel the lack of an affordable solution from a major provider like AWS.
We have good news though: there wasn’t an alternative hosting solution at the time the survey was going out… but there is something out there now! CouchDB Minihosting is not quite a complete scalable hosting solution, but it’s a no-brainer way to get started with a CouchDB hosted on your service of choice.
“100 million documents (and counting) and constant read/write operations”
Conclusion
If you’re familiar with CouchDB, this survey will confirm what you already know: CouchDB’s reliability, seamless replication, and the HTTP API remain unmatched. The guiding principles behind it have created a one-of-a-kind technology with very loyal users, and the addition of features like Nouveau continue to expand its appeal.
Naturally there is room for growth, particularly when it comes to queries and hosting. With newer query enhancements being added and refined, like Nouveau in beta, it will be interesting to see how these themes evolve.
So — what’s the verdict? CouchDB remains the gold standard for distributed systems and continues to be a mainstay when it comes to offline-first applications. Its next leap may start with even wider adoption in the local-first community.
Thank you to all who contributed their time to completing the survey. Until next time!
« Back to the blog post overview