First Steps with Nouveau, CouchDB’s New Full-Text Search posted Thursday, October 24, 2024 by Alex TutorialCouchDB
With Version 3.4.1, CouchDB added Nouveau, a brand-new implementation of search using Lucene. After announcing the feature in a previous post, we now dive deeper into Nouveau and try out fuzzy search, facets, counts and ranges, while of course also covering the installation and setup, and some performance considerations.
- Nouveau in a Nutshell
- Let’s set up Nouveau!
- Nouveau Index Field Types
- Full-text Search with Nouveau
- Facet Queries with Nouveau
- Nouveau Disk Usage and Performance
- Conclusion
Nouveau in a Nutshell
Let’s briefly cover what Nouveau actually is:
- Full-text search for CouchDB
- A from-scratch reimplementation of search with Lucene
- Currently an experimental beta feature
- A future replacement for Clouseau/CouchDB Search
- Way more flexible than CouchDB views or Mango
There were good reasons to write a new search implementation from scratch, primarily to do with the fact that the predecessor, Clouseau, was implemented in Scala with Scalang. Scala devs are rare, and Scalang is effectively end-of-life, which locked us out of newer Lucene features. Nouveau is written in modern Java with the latest Lucene, which makes it more efficient, more easily maintainable, and gives us access to all the latest Lucene features. All in all, a big win!
Let’s Set up Nouveau!
There are just three steps we need to complete before we can query all the things:
- Configure your CouchDB (3.4.1 or newer) to use Nouveau
- Start a Nouveau server
- Write a Nouveau index
1. Configure CouchDB to Use Nouveau
All you need to do is add a Nouveau section to the config and restart CouchDB to enable the feature:
[nouveau]
enable = trueYou can also do this in Fauxton if you like, with out a restart. As a third alternative, you can also set this value via http for each node in your cluster, which will also work without a restart:
curl -u admin:pass http://127.0.0.1:5985/_node/_local/_config/nouveau/enable -X PUT -d '"true"'Relevant CouchDB Documentation page
2. Start the Nouveau Server
Since Nouveau ships with CouchDB as a .jar file, all you need to do is find it and start it. However, you’ll need a Java runtime to run it, so let’s take care of that first:
- Check whether you have a Java runtime, eg. as a Homebrew user with:
brew info openjdk. Anything >= Java 11 is fine. - If you don’t have one, install one!:
brew install openjdk - Do check the installer output for a
Caveatssection at the end, you may need to symlink some stuff - Check whether it works:
▸ java -version openjdk version "23" 2024-09-17 OpenJDK Runtime Environment Homebrew (build 23) OpenJDK 64-Bit Server VM Homebrew (build 23, mixed mode, sharing)
Nice. We said Nouveau is part of CouchDB, but depending on your OS and CouchDB release the exact path may vary. On MacOS, for 3.4.2, it’s:
/Applications/Apache CouchDB.app/Contents/Resources/couchdbx-core
/nouveau/lib/nouveau-1.0-SNAPSHOT.jarFrom the couchdbx-core directory, start Nouveau:
java -jar nouveau/lib/nouveau-1.0-SNAPSHOT.jar server etc/nouveau.yamlAnd then leave it running. It will try to shut down cleanly on a TERM signal, but it is also completely safe to kill the JVM, although anything not committed to disk at that point will be lost.
Relevant CouchDB Documentation page with additional Nouveau config options
3. Define a Nouveau Index
This is very similar to what you’re used to from views. Quick refresher, views look a bit like this:
{
"_id": "_design/view_example",
"views": {
"indexName": {
"map": "function(doc){
if (doc.name) { emit(doc.name, true)}
}
}"
}
}
}⚠️ Note: In all of these examples, we’ve added line breaks to the indexing functions for readability. Please omit these in actual design docs.
- First, set up a design doc and define a Nouveau index, which consists of JavaScript functions that run for every document in the database and emit index fields.
- Then, send a http query to it.
Since each index depends on what you want to query, we’ll actually be writing several of these. But before we can start, we need to know about the types of index fields we can use, and then we’re going to start with a full-text search example.
Nouveau Index Field Types
Currently, Nouveau supports four Lucene index field types, all of which we will try out in the course of this post:
text- Can do: full-text search, stemming, wildcards, regex, fuzzy matching, case-folding, word proximity
- Can not do: sorting, range queries and faceting
string- Can do: sorting, counting and faceting
- Can not do: amazing search feats like
text - Can be searched if the
keywordanalyser is specified - Can only take strings (use
.toString()etc.)
double- Can do: sorting, range queries and range faceting
- Can only take numbers (use
parseInt()etc.)
stored- A stored field stores the field value into the index without analysis. The value is returned with search results but you cannot search, sort, range or facet over a stored field.
- All other types can also return the stored field
CouchDB Documentation page for Nouveau index field types
For a full-text search, we’ll start with a text index.
Full-Text Search with Nouveau
First off, we need some example data. We’re using a little script using faker.js to generate a couple of thousand products, and it’s come up with gems like this one:
{
"_id": "00129778-b92b-4f1e-86bc-182eedca6470",
"name": "Recycled Rubber Computer",
"description": "The Football Is Good For Training And Recreational Purposes",
"department": "Baby",
"price": 843.89,
"material": "Concrete",
"colors": [
"lime",
"lavender"
],
"rating": 0.24,
"numberOfRatings": 790
}What might we want a full-text search to cover here? Name, description, department, material, colors, but not the others. So let’s add these to the index. First, we need a design doc with a nouveau object. Each key in that object is an index, and the key will be the name of that index. The value will be the indexing function, run once per document in the database:
{
"_id": "_design/nouveau_example",
"nouveau": {
"full-text": {
"index": "function(doc){
// function body
}
}"
}
}
}Inside the indexing function, you have the doc and an index() method that lets you actually emit an index field. You can read up on the details in the CouchDB Docs on Nouveau Index Functions. For now, it’s sufficient to know that the arguments to index() are the field type, the field name, and the field value.
So let’s emit things! Let’s start with a single field for now:
{
"_id": "_design/nouveau_example",
"nouveau": {
"full-text": {
"index": "function(doc){
if (doc.name) { index('text', 'name', doc.name) }
}"
}
}
}⚠️ Note the guard clause around the index() call! Runtime errors will cause the document to not be indexed, so do your best to guard against these.
If this were in a db named nouveau-test, you could return the entire index with
curl -X GET 'http://admin:admin@127.0.0.1:5984/nouveau-test/_design/nouveau_example/_nouveau/full-text?q=*:*' | jqNote: you can of course also use POST instead of GET.
Our selector, denoted q, is *:* here, which will return everything in the index. This doesn’t really constitute a search, so let’s be more specific in our use of q, which generally expects its value to be in the format fieldName:fieldValue:
curl -X GET 'http://admin:admin@127.0.0.1:5984/nouveau-test/_design/nouveau_example/_nouveau/full-text?q=name:cheese' | jqNow, we don’t want to do a name-text search, we want to do a full-text search, so we need to index more fields.
The correct way to do this for a full-text search is to build a single index field that concatenates the full-text of each doc:
{
"_id": "_design/nouveau_example",
"nouveau": {
"full-text": {
"index": "function(doc){
let text = ''
if (doc.name) { text += doc.name + ' ' }
if (doc.description) { text += doc.description + ' ' }
// add more fields here
if (text) { index('text', 'default', text) }
}"
}
}
}Note that we’ve cleverly named our index default this time, which is a reserved value, and this allows us to omit the field name in the query:
curl -X GET 'http://admin:admin@127.0.0.1:5984/nouveau-test/_design/nouveau_example/_nouveau/full-text?q=cheese' | jqThis should return all documents with cheese in their index value somewhere (only showing one hit here for brevity):
{
"total_hits_relation": "EQUAL_TO",
"total_hits": 513,
"ranges": null,
"hits": [
{
"order": [
{
"value": 1.4125464,
"@type": "float"
},
{
"value": "00856db8-d258-4292-bb15-9759f15e261c",
"@type": "string"
}
],
"id": "0c92a877-fa7a-425b-9bbb-842203d2c213",
"fields": {}
},
…
],
"counts": null,
"bookmark": "W1t7InZhbHVlIjoxLjQxMjU0NjQsIkB0eXBlIjoiZmxvYXQifSx7InZhbHVlIjoiMWMzM2U4MmItNTBjZC00ODBlLTg1NDQtODA0MjM0ZjQ1ZjljIiwiQHR5cGUiOiJzdHJpbmcifV1d"Now, this isn’t a particularly insightful response, so let’s include_docs:
curl -X GET 'http://admin:admin@127.0.0.1:5984/nouveau-shop-test/_design/nouveau_example/_nouveau/full-text?q=cheese&include_docs=true' | jqNow each hit also includes the full document. Alternatively, we could change our index function to return the field value with the hit, by passing in the optional fourth parameter:
index('text', 'name', doc.name, {'store': true})This works like the fields option in Mango and will populate the previously empty fields: {} object in the response with the keys and values of each index field. In any case, we now know what we’re looking at.
With everything being emitted into a single index field, we can now easily search for multiple words (just showing the exciting bits from now on, not the whole curl invocation):
q=cheese footballThis will return all docs that contain cheese and possibly football anywhere in our composite index value. I say “possibly” because we haven’t explicitly told Nouveau which relationship these two words have (such as in q=cheese AND football or q=cheese OR football or q="fresh cheese"), so it might eventually give us results without football and rank them lower than the results that contain both words.
As you can see, you can use logical operators in your queries, which are also explained in the docs. More examples for those later.
For completeness sake, here’s our full index function that also handles the array of colours each product has:
function(doc) {
let text = ''
if (doc.name) { text += doc.name + ' ' }
if (doc.description) { text += doc.description + ' ' }
if (doc.department) { text += doc.department + ' ' }
if (doc.material) { text += doc.material + ' ' }
if (doc.colors) { text += doc.colors.join(', ') + ' ' }
if (text) { index('text', 'default', text) }
}Now let’s briefly look at the wrong way of building a full-text index: emitting one index field per value in the doc.
Let’s start with the name and description, and emit each as their own index field:
{
"_id": "_design/nouveau_example",
"nouveau": {
"full-text": {
"index": "function(doc){
if (doc.name) { index('text', 'name', doc.name) }
if (doc.description) { index('text', 'description', doc.description) }
}"
}
}
}Now if we try to do a query, the request gets a little smelly, and not just because of the cheese. We’ve indexed two values into two index fields, so now we need to search across both of them individually:
q=name:cheese OR description:cheeseHm. This isn’t going to scale well, is it? Imagine we were indexing 10 fields per doc, you’d need to know about and specify all of them in every query:
q=name:cheese OR description:cheese OR whatever:cheese OR … OR … OR ……which is much more verbose and complicated than what we had before:
q=cheeseThat’s a lot better. And imagine: things would have escalated even more disgustingly had we queried for multiple words! For full-text search, only emitting a single index field to the default field is definitely the most elegant way to go.
Now, on to the spicy bit:
Fuzzy Full-Text Search
If we’re getting these search phrases from users, we shouldn’t trust that they will spell everything correctly. To use fuzzy search in Lucene, we need to append ~ to each fuzzy search term, so we’ll split and join the queries into a fuzzy search like this:
q=cheeeese~ AND fooball~ AND olvie~And this will return all olive-coloured football cheeses, or all cheese and olive-flavoured footballs, and at this point I can no longer pretend this data set is in any way plausible 🤷♂️
In any case, it turns out fuzzy full-text search in CouchDB is pretty simple to achieve now. You can get a lot fancier if you like! You can:
- Alter the importance of a search term by adding
^and a positive number - Use the single-char
?wildcard:dat?would matchdateanddata - Use the multi-char
*wildcard:dat*would matchdate,data,database, anddates - Use regex!
/[ta|reli]able/ - And use the aforementioned logical operators
AND,+,OR,NOTand-
Sweet. Let’s try facets next.
Facet Queries with Nouveau
You probably know facet queries from using e-commerce sites: “show me all hi-top sneakers in black or tan in size 45 from 90€ to 150€ with at least 50 reviews with an average review score of 4”. Each of these attributes is a facet, and we often want to query across multiple of these, sometimes with values (black, tan, hi-top sneakers), sometimes with ranges (price, review count, review score), and often with logical operators to combine all of them in various ways (OR, AND, NOT).
Facets work a little differently than full-text searches:
- We need to use field types that support faceting, so
textis out, andstringanddoubleare in. - We need to emit multiple index fields per doc, not one.
- We need to construct our index so that all documents emit the same set of index fields. This means we can’t have a guard clause around each
index()call, as we did previously. Instead, we need a single guard clause around allindex()calls, checking for the presence of any value used in them.
For our products db, that would mean an index function that looks a bit like this:
function(doc){
if (doc.price && doc.rating && doc.department && doc.material && doc.numberOfRatings && doc.colors) {
index('double', 'price', doc.price, {"store": true});
index('double', 'rating', doc.rating, {"store": true});
index('double', 'numberOfRatings', doc.numberOfRatings, {"store": true});
index('string', 'department', doc.department, {"store": true});
index('string', 'material', doc.material, {"store": true});
if (doc.colors) {
for(var i in doc.colors) {
index('string', 'color', doc.colors[i], {'store': true})
}
};
}
}Now we can do facet queries:
q=department:music AND price:[50 TO 150]or just query ranges of facets
q=rating:[4 TO 5] AND numberOfRatings:[800 TO *] AND price:[100 TO 200]or combine all sorts of facets
q=color:(ivory OR indigo) AND price:[50 TO 100] AND department:automotive AND rating:[4 TO *]You can even nest and combine logical operators across fields!
q=NOT (material:frozen OR material:granite OR department:industrial) AND price:[100 TO 150]…and even within fields:
q=price:[50 TO 150] NOT price[100 TO 120]And, as you could see from color, you can emit multiple times for the same field name.
Facet queries can also be extended with counts and ranges, which we’ll briefly cover before taking a peek at what the performance implications of adding full-text search with Nouveau are.
Facet counts
Counts simply count how many different values any index field has. Adding
?counts=["department", "material"]to our queries will add a counts object to our response:
"counts": {
"material": {
"wooden": 5,
"steel": 9,
"soft": 7,
"rubber": 15,
"plastic": 10,
"metal": 10,
"granite": 5,
"frozen": 12,
"fresh": 9,
"cotton": 12,
"concrete": 10,
"bronze": 10
},
"department": {
"toys": 4,
"tools": 5,
"sports": 9,
"shoes": 10,
"music": 3,
"jewelry": 4,
"industrial": 9,
"home": 3,
"health": 5,
"grocery": 3,
"garden": 4,
"computers": 8,
"clothing": 3,
"books": 4,
"beauty": 5,
"baby": 3,
"automotive": 5
}
}You can add a top_n parameter if you want more or fewer results here (max is 1000).
Facet ranges
Ranges let you categorise documents by arbitrary facet ranges. Say your shop UI would like to display how many “cheap” and how many “expensive” products there are, and this range is somehow determined by the customer’s previous purchases, you could add the following to your query (formatting for readability):
?ranges={"price":[
{"label":"cheap","min":0,"max":100, "max_inclusive": false},
{"label":"expensive","min":100}
]}This will add a ranges object to the response:
"ranges": {
"price": {
"expensive": 10858,
"cheap": 1230
}
}Also pretty nifty. But what will it cost you to do all of this?
Nouveau Disk Usage and Performance
First off, Lucene is pretty much the top of the line when it comes to full-text search engines, so it’s unlikely you’ll find more efficient options. That being said, you will be building additional indexes, and it’s worth knowing what you’re signing up for with Nouveau. The key value here is the size of the indexes on disk, so we’ll look at a couple of examples for that with different data sets, index compositions, and database sizes.
Let’s first look at the indexes we’ve built in this blog post so far.
Full-Text Search Index Disk Usage and Performance
Using the full-text index from the examples above, queried with a fuzzy search for q=cheeese~ OR fotbal~.
Graph of the query response times vs. number of documents in the database
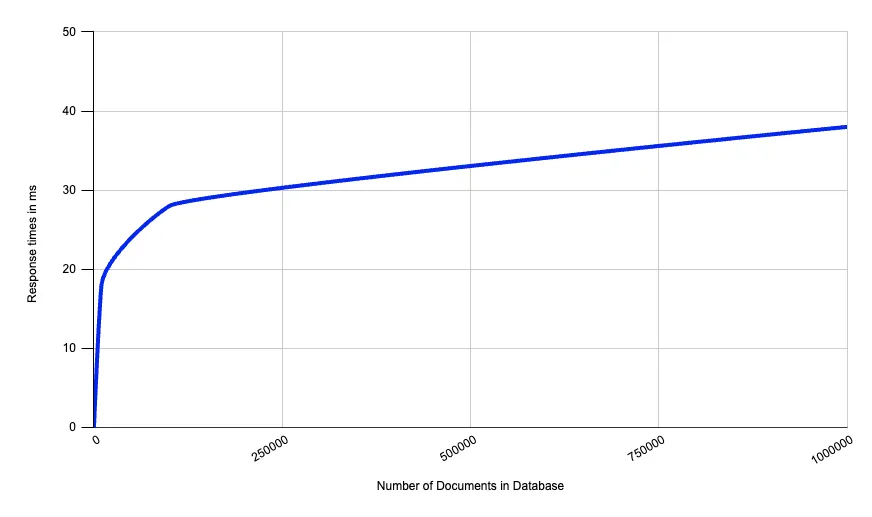
| Number of docs | Size on disk | Response times |
|---|---|---|
| 10.000 | 2MB | ~18ms |
| 100.000 | 18MB | ~28ms |
| 1.000.000 | 200MB | ~38ms |
So an order of magnitude increase in documents roughly results in an order of magnitude increase in index size, which is expected. More interestingly, the response times are roughly log-scale, meaning they only double for every time the document count grows by an order of magnitude.
🤔 How was this measured and on what?
- CouchDB was set up with
q=2, so with two shards. For the disk size per shard, divide the given numbers by 2. - Disk sizes were measured with the
_nouveau_infoendpoint. - CouchDB, Nouveau and the test requests were all running on the same dev machine.
- Hardware used was a 2020 M1 Mac with 16GB RAM, with the usual dev load going on at the same time (10 iterm tabs, 5 VSCode instances, about 50 browser tabs and Spotify 😅).
- Requests were made and measured using Thunder Client for VSCode.
Faceted Catalogue Search Index Disk Usage and Performance
Using the facet index from the examples above, queried with q=rating:[4 TO 5] AND numberOfRatings:[800 TO *] AND price:[100 TO 200], with counts and ranges:
| Number of docs | Size on disk | Response times |
|---|---|---|
| 10.000 | 0.5MB | ~10ms |
| 100.000 | 17MB | ~15ms |
| 1.000.000 | 185MB | ~30ms |
Email Inbox Search Index Disk Usage and Performance
This example assumes we’re trying to render a searchable email inbox with previews for each email. We’d like to full-text search the from, to, subject and body, but only want to return the data we’ll actually be displaying for the email previews, so only the first 100 characters of the body. The corresponding Nouveau index function looks like this:
function(doc){
// Omitting guard clauses for brevity
// We’re indexing the full email body…
index('text', 'default', doc.from + ' ' + doc.to + ' ' + doc.subject + ' ' + doc.body );
index('stored', 'from', doc.from);
index('stored', 'to', doc.to);
index('stored', 'subject', doc.subject);
// …but only returning the first 100 characters
index('stored', 'bodyexcerpt', doc.body.substring(0, 100))
}This gives us Nouveau search hits that look like this:
{
"order": [
{
"value": 0.27000123,
"@type": "float"
},
{
"value": "a8944da3-1901-4ffc-942b-40eb1d61d3e0",
"@type": "string"
}
],
"id": "a8944da3-1901-4ffc-942b-40eb1d61d3e0",
"fields": {
"to": "Enos_Pfannerstill@example.org",
"subject": "Altus vehemens concedo ago compono suus tonsor demergo.",
"from": "Stuart34@example.net",
"bodyexcerpt": "Defungo sono utique vetus. Aeger deprimo concedo tempore delectus. Caterva vapulus asperiores laudan"
}
}For 100.000 email documents with between 1 and 5 paragraphs of body text, the database size on disk is 112.42MB, and the index size on disk is 41.74MB. Response times for a fuzzy search are speedy, mostly under ~20ms.
If you want to try this yourself, here’s the script used to generate the email documents.
Conclusion
Nouveau rocks. It’s simple to set up, easy to use, extremely capable and flexible, and face-meltingly fast. Give it a spin today! Remember, it’s still in beta, so you might run into some occasional weirdness or undocumented detail. In any case, the CouchDB team would be extremely grateful if you shared your experiences with Nouveau:
- The CouchDB project runs a Slack workspace.
- On GitHub, there are Discussions and Issues.
For more in-depth advice on Nouveau and CouchDB in general, we’re available as consultants. You can get in touch with us by sending an email or booking a call.
« Back to the blog post overview